


算力资本是大模子应用升起的前提,是下一代AI狡计架构需要惩处的最中枢问题。
当大模子训推需求份额已占据过半的算力需求时,硬件层上针对大模子的转换却历历,芯片瞎想险些成为制程工艺的隶属。
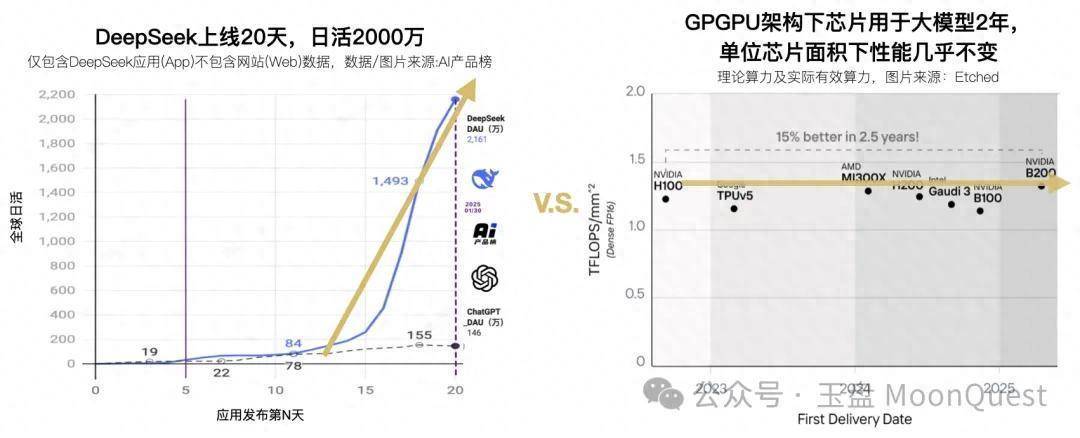
应用需求 vs 基础顺序供给
类GPGPU架构支捏了AI大模子快速崛起,但其难以兼顾通用性和对大模子的针对性,在面对模子范围和复杂性的急剧蔓延时,自后果与资本的黑洞被诟病已久,以致仍是影响商场对大模子改日发展的预期。
玉盘MoonQuest团队充分拆解不同角度的算力问题(内存墙、存储墙、功耗墙等),合计中枢都是I/O问题(数据的读写与搬运后果太低),制约了硬件表面算力的充分发达,算力资本问题有进一步制约了通盘这个词行业的发展。
本文旨在忽视一种从I/O起程、专为AI大模子训推瞎想的转换狡计架构——SRDA(系统级极简可重构数据流架构 System-level Simplified Reconfigurable Dataflow Architecture ),辅以一份更为留意的架构白皮书,无缺开源SRDA的架构理念、技巧上风以及初代的中枢组件,探讨从I/O优化角度起程克服现存算力资本瓶颈的新念念路。
AI狡计需求的演进与挑战东说念主工智能,尤其是深度学习,在昔时十年中赢得了显赫进展。AI模子,至极是Transformer、Diffusion等架构的出现,使得模子参数目从数百万激增至数千万亿级别,胜仗导致了对狡计资源,尤其是并行处理才略和内存带宽的极致需求,传统狡计架构安靖透露多重制约:
性能栽植依赖制程工艺:昔时3年,工艺栽植带来的单元面积算力优化惟一15%,而主流不雅点合计刻下芯片工艺极限约1nm,先进制程难以随着大模子一齐scale.内存带宽为止:现存主流类GPGPU架构选拔的多级分享式内存(如HBM)在多线程并发打听时,读写冲突以及数据过度随即化极易产生显存打听拥塞,导致内存带宽每每成为推行应用中的瓶颈,尤其在处理巨型AI模子时问题愈加严重。算力期骗率低:由于架构瞎想、通讯支出以及内存打听瓶颈等多重身分制约,芯片的表面峰值算力在推行AI负载中无法充分发达。功耗屡转换高:顶级AI加快器芯片的功耗方针屡转换高,已成为制约其更平凡应用和可捏续发展的中枢瓶颈。以英伟达H100 GPU为例,其典型板卡功耗高达700瓦,基于光模块的超节点集群决策更是功耗惊东说念主。这是类GPGPU架构依靠加多狡计核来拉高算力导致的,算力增幅与功耗增幅险些成正比。大范围集群扩展清贫:传统两层网络(节点内高速互联如NVLink,节点间网络如InfiniBand/以太网)的瞎想,带来了带宽层级相反、公约编削支出、通讯治理复杂等诸多问题,不得不占用无数狡计资源来扩充通讯任务。软件复杂:现存AI加快决策的主流软件栈十分复杂,推行算力期骗率低,而优化资本十分高,进一步为止了其在大模子领域的应用。面对这些挑战,业界亟需转换的狡计架构来冲突现存瓶颈,得志AI大模子发展的技巧需求。
SRDA:为AI大模子极致算力性价比瞎想的新狡计范式SRDA 系统级精简可重构数据流架构是一种以数据流为中心、软硬件协同瞎想的AI狡计架构,强调在老到工艺下通过架构转换终了性能冲突的后劲。其中枢瞎想理念是通过数据流驱动狡计,研究极简和可重构念念路,最大轨则地栽植AI狡计的后果、天真性和可扩展性。
瞎想形而上学SRDA的瞎想形而上学根植于对AI狡计负载特质的深远明白:
数据流驱动:AI狡计,尤其是神经网络的历练和推理,骨子上是大范围、结构化的「数据流」处理过程(数据在狡计节点间依照特定狡计图(Compute Graph)进行流动和编削)。传统GPGPU类的「戒指流」架构(Control-Flow Architecture)下,SIMT架构同样复杂的多级分享内存架构导致内存打听每每成为性能瓶颈,致使狡计单元万古刻闲静和高额的数据搬运功耗。SRDA 将「数据流」的优化置于架构瞎想的中枢(Data-Flow Architecture)。SRDA通过编译器解析狡计图,定制优化旅途,将狡计图拆解后胜仗静态映射到硬件,终了数据在狡计单元之间点到点胜仗传输,大幅减少了对中央内存的依赖和打听次数。这种瞎想理念从根蒂上减少了数据移动的距离和频率——这亦然刻下大模子狡计系统中主要的性能和能耗瓶颈之一。通过让数据“流动”起来,让狡计“跟班”数据,SRDA最大化灵验狡计的占比,最小化恭候和搬运的支出。软硬件超交融:为充分发达硬件后劲,SRDA从瞎想之初就强调硬件架构与软件系统的超交融瞎想。这并非简单地为已有的硬件开导软件,而是在架构界说阶段就将软件精简性和易用性手脚中枢方针。(这亦然玉盘仅20余东说念主参加的中枢发轫,咱们合计高效是AI时期的势必条款)SRDA的编译器对硬件的可重构特质、内存系统的架构与打听特质、以及互联网络的拓扑与通讯特质领有精准的明白。这使得编译器好像在编译阶段进行全局的静态优化,举例:将狡计图高效地映射到物理狡计单元,精准操办数据在片上和片间的传输旅途,优化内存打听样子,以及事前建设数据通顺道以放置初始时治疗支出。这种深度的超交融瞎想,使得SRDA好像终了传统通用架构配合通用编译器难以企及的优化水平,从而将硬件的表面性能更充分地转变为推行应用性能。同期,SRDA软件栈也致力于于对表层AI框架(如PyTorch、JAX及更表层的训推框架)提供神圣的接入层接口,使开导者毋庸感知底层硬件就好像高效期骗SRDA的雄壮才略。精简与高效:SRDA追求用最胜仗、最高效的式样得志AI狡计的中枢需求。面对AI狡计负载的专用性,SRDA弃取剥离传统通用处理器中为支捏各样化任务而引入的复杂戒指逻辑、冗余教唆集以及多级缓存一致性等机制。手脚一种AI领域的专用架构,SRDA将硬件资源更聚焦于AI狡计本人的中枢操作,如张量运算、向量处理等。 这种架构上的精简带来了多重效益:更高的面积后果:在疏导的芯单方面积下,不错集成更多的灵验狡计单元和片上内存,胜仗栽植原始狡计才略。更高的动力后果:减少了非狡计干系的晶体管举止和复杂戒指逻辑的能耗,使得每一瓦特电力都能更灵验地转变为灵验算力。更低的复杂度:底层基于开源RISC-V教唆集生态,大幅简化了教唆系统和算子开导难度。同期,精简的架构也意味着芯片和系统的开导复杂度更可控,能更好的助力芯片瞎想团队及改日的用户大幅责骂开导资本。可重构性与得当性:SRDA是为AI领域瞎想的专用架构,但并非僵化的固定模子的硬件加快器。AI算法和模子本人在快速演进,从经典的CNN、RNN到主流的Transformer,再到新兴的MoE(夹杂行家模子)、Mamba(景况空间模子)、DiT(Diffusion Transformer)、ViT(Vision Transformer)等,其狡计特质和数据流样子各不疏导。 SRDA的重要特质之一是其可重构性,硬件的数据旅途、部分狡计单元的功能组合以及内存打听样子,不错在一定进度上由软件字据具体的AI模子或狡计任务进行建设和优化,终了:得当各样化的模子结构:针对不同模子的突出狡计需求(如不同类型的谨慎力机制、轮回结构或寥落狡计样子),建设最优的硬件扩充决策。优化特定运算层:专科用户不错针对模子中的不同狡计层或重要算子,进行细粒度的硬件资源匹配和数据流定制。面向改日模子架构的扩展性:为改日可能出现的新式AI算法和模子架构预留了得当空间,幸免了因架构固化而过早被淘汰的风险。 通过这种受控的可重构性,SRDA™辛勤在专用加快器的高后果与通用处理器的高天真性之间赢得逸想的均衡,以捏续高效地支捏AI技巧的快速发展。重要技巧模块与惩处决策源于深厚I/O技巧蓄积和商场需求细察,玉盘SRDA凭借系统级数据流、溜达式3D堆叠内存系统、I/O交融互连技巧、极简可重构等多项重要技巧模块,终了极简且高效的软硬件超交融SRDA架构,系统性惩处刻下算力濒临的中枢挑战。
QDDM™:溜达式片上3D堆叠内存治理技巧
为了冲突“内存墙”的为止,SRDA选拔了QDDM™(Distributed 3D DRAM Management)技巧 。该技巧期骗先进的3D堆叠工艺,在狡计芯片上胜仗集成了高带宽、大容量的溜达式内存网络。QDDM™的重要特质包括:
狡计单元内存突出化:每个狡计中枢或狡计簇领有其突出的、紧耦合的内存区域,自然支捏带宽阻隔,放置了多中枢分享内存带来的带宽竞争和打听冲突。3D-DRAM专用戒指技巧:集成定制的3D-DRAM戒指器,在提供高带宽期骗率的同期,可灵验镌汰数据传输旅途和打听延迟,并定制了专用的数据加快功能。良率栽植决策:针对3D堆叠技巧可能带来的良率挑战,SRDA™选拔了的专用良率决策,确保了大范围坐褥的可行性和资本效益。QLink™:交融高速互连通讯技巧在大范围AI狡计集群中,节点间的通讯后果是决定举座性能的重要身分。SRDA为此引入了QLink™交融高速互连技巧 。QLink™旨在构建一个单层的调解、高效、低资本的互连网络,支捏原生all-to-all的从芯片里面核间、芯片间(chip-to-chip)到业绩器节点间(node-to-node)的无缝互连。
交融网络架构:将传统数据中心中可能并存的多种网络(如scale-up与scale-out网络)交融成调解的QLink™网络,简化网络拓扑,责骂治理复杂度和部署资本,且无需欢乐的专用网卡。孤独通讯引擎:QLink™集成了自研的孤独通讯治疗引擎,终清醒狡计任务与通讯任务的王人备解耦。通讯操作由挑升的硬件处理,不占用贵重的中枢狡计资源,开释更多灵验算力。高带宽与低延迟:QLink™提供高速互联带宽和低延迟特质,为大范围并行历练和溜达式推理提供雄壮的通讯撑捏。线性扩展与高可靠性:集成了自研的增强型网络模块,灵验责骂数据拥塞,支捏大范围AI集群(如十万卡级别)的近乎线性扩展,并增强了系统可靠性。极简AI编译器与协同瞎想的软件栈SRDA架构的雄壮才略需要高效的软件栈来开释。为此,玉盘开导与硬件架构缜密协同的极简AI编译器和软件器具链 :
基于开源RISC-V生态:底层基于开源的RISC-V教唆集生态,简化了底层算子的开导和优化难度,同期也为架构的盛开性和社区合作提供了基础。聚焦中枢与静态编译:编译器聚焦AI狡计的中枢功能,责骂了系统复杂度。通过支捏静态狡计图优化和静态编译,好像在编译期间完成大部分的优化责任,为可重构数据流旅途的建设和资源治疗提供精准蛊惑。兼容主流AI框架:前端接口瞎想留意与主流AI开导框架(如PyTorch、JAX以及表层的vLLM)的兼容性,使得用户不错平滑转移现存的模子和开导历程。训推一体与资源优化:软件栈对推理、预历练和后历练等不同AI应用场景进行了再行瞎想和优化,以充分期骗SRDA架构在算力、内存和通讯方面的硬件上风,最大化资源期骗率。在集群层面,终了对网络、狡计、存储的调解治理和高效期骗。高性能交融狡计引擎与可重构数据流与传统固定功能的狡计单元不同,SRDA的狡计单元支捏字据AI模子的具体算子和数据依赖关系,动态构建和优化狡计旅途。这种可重构的数据流使得中间狡计扫尾不错在狡计单元之间胜仗点到点传输,无需普通打听片外主存,从而极大减少了数据搬运支出,放置了数据拥塞,显赫提高了推行算力期骗率 。
该狡计引擎至极针对AI责任负载进行了优化,定制了专用的狡计单元以大幅栽植峰值算力。此外,玉盘首颗SRDA芯片将原生支捏FP8等主流趋势的低精度数据类型,关于责骂内存占用、栽植狡计微辞量至关遑急,并能与选拔FP8原生模子精度的前沿模子高效配合。狡计单元还支捏天确凿狡计组合,保证了较强的通用性。
“当下是鼓舞AI专用狡计架构的最恰那时机”SRDA架构将:大幅栽植算力期骗率:通过可重构数据流、存算联一体化瞎想以及狡计通讯解耦,大幅减少数据搬运和通讯恭候,栽植灵验狡计时刻占比。大幅优化内存带宽与后果:大幅优化超高内存带宽和低延迟打听,灵验缓解大模子应用中的内存瓶颈。高效费比的大范围集群扩展:IO交融技巧简化了网络部署,责骂了互联资本,并支捏构建高后果的超大范围AI狡计集群。不依赖先进制程拉高算力:基于老到的工艺制程即可终了高灵验算力。大模子场景最优总领有资本(TCO):通过栽植单芯片/单节点性能、大幅责骂功耗、责骂集群构建和运维复杂度、以及选拔恰当的老到制程工艺,旨在提供更优的举座TCO。天确凿模子与算法得当性:可重构数据流和对多种数据精度的支捏,使得SRDA有才略天真得当不断演进的AI模子和算法。极简的软件开导与转移:兼容主流框架并简化底层软件栈,责骂用户的使用门槛。下一步
SRDA不仅关怀芯片单点性能的栽植,更着眼于举座数据中心系统。咱们但愿SRDA在鼓舞AI技巧普惠化、赋能下一代AI应用、探索狡计架构发展以及构建自主可控的AI算力基础顺序等方面发达作用,为智能时期的加快到来孝敬力量:
重塑数据中心与智能算力网络:QLink™等互联技巧的转换,不仅优化了单业绩器里面的通讯,更为构建高效、低资本、易扩展的超大范围AI数据中心(“AI token工场”)提供了新的惩处决策。改日,SRDA的理念和技巧也可能延迟至旯旮狡计乃至端侧诞生,得志不同场景下对高效AI处理才略的需求,为构建泛在的智能算力网络孝敬力量。赋能下一代AI大模子与复杂应用:刻下AI模子正朝着更大参数范围、更复杂结构(如多模态交融、长程依赖处理)的主义发展。SRDA™提供的超高推行算力、超大内存带宽和容量、各种精度掩饰,将为这些刻下受限于硬件才略的下一代AI模子的历练和部署提供坚实基础,催生出愈加智能和雄壮的AI应用。探索AI狡计架构的范式演进:手脚一种专为AI瞎想的领域专用架构,SRDA以数据流为中心的瞎想理念,以过头在溜达式内存系统和交融网络上的转换,对传统以戒指流为主、依赖分享内存和分层网络的通用狡计架构组成了遑急补充和发展。基于此,咱们有望进一步鼓舞AI芯片瞎想向更深档次的软硬件协同优化和专用化主义发展,加快酿成针对不同AI负载特征的异构狡计生态。SRDA所强调的可重构性,也为应答在transformer之上进一步快速迭代的AI算法提供了天真性,咱们但愿和各方模子伙伴探索演进。构建盛开与互助的生态系统:咱们期待围绕SRDA架构,与AI框架开导者、模子商酌社区、行业应用伙伴以及落魄游供应链企业伸开深度合作。通过盛开部分硬件细节、提供完善的SDK和开导器具、共同界说和优化落魄游重要组件与芯片的协同(“芯云一体”、“芯模一体”、“算电一体”等),旨在构建一个活跃、共荣的开导者和用户社区,加快SRDA技巧的普及和转换应用。结语当一个场景的技巧需求走向拘谨,商场需求从小范围科研走向大范围应用,底层基础顺序由专用架构替代通用架构终了最高性价比险些是商场的势必弃取,从图像娇傲商场GPU替代CPU,到矿机商场矿卡替代GPGPU。
玉盘MoonQuest团队从芯片、Infra、应用等不同角度看到了刻下AI狡计架构下算力瓶颈给AI发展带来的为止,于2025年的今天忽视SRDA架构,并推出接下来的干系芯片,不仅是咱们对刻下AI算力瓶颈的复兴,亦然尝试对改日AI狡计领域的发展可能性忽视一次“天问”(A Moonquest)。
近期DeepSeek团队在其新论文《Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures》中从芯片用户角度对改日AI硬件忽视了一些期待,其中好多点和SRDA架构的念念路殊途同归,也让咱们更有信心SRDA架构有契机成为下一代针对AI大模子场景的更优狡计架构。
咱们期待除玉盘外,改日有更多AI大模子狡计芯片辩论SRDA,继模子层、Infra层之后,在硬件层也助力加快AGI的到来。
《SRDA狡计架构白皮书》:
https://github.com/moonquest-ai/SRDA/tree/main
— 完 —
量子位 QbitAI · 头条号
关怀咱们买球的app排行榜前十名推荐-十大正规买球的app排行榜推荐,第一时刻获知前沿科技动态